In Google We Trust?
Skip other details (including permanent urls, DOI, citation information)
: This work is protected by copyright and may be linked to without seeking permission. Permission must be received for subsequent distribution in print or electronically. Please contact mpub-help@umich.edu for more information.
For more information, read Michigan Publishing's access and usage policy.
Abstract
Trust, authority, and reputation are central to scholarly publishing, but the trust model of the Internet is almost antithetical to the trust model of academia. Publishers have been so preoccupied with the brute mechanics of moving content to the online world that they have virtually ignored the challenge that the Internet trust model poses to the scholarly publisher. Publishers can learn much about approaches to handling Internet trust from the actions of major online players outside the publishing industry. Publishers should also benefit from watching the trust models that are being experimented with in the nascent realm of social software applications. Publishers once led the way in establishing the apparatus of trust during the transition from manuscript to print culture in early modern Europe. Ultimately, publishers should again take the lead in helping to establish new mechanisms of trust in what could reasonably be described as "the early modern Internet."
Every day, Internet users are pelted with spam, hoaxes, urban legends, and scams - in other words, untrustworthy data. The Internet is largely without any infrastructure to help users identify authoritative and trustworthy content. Indeed, the history of the Internet is littered with examples of how technologists have underestimated the crucial role that social trust and authority play in communication.
Authority is the sine qua non of academic publishers and librarians, and the trust model of the Internet is almost completely antithetical to the model of scholarly trust that has evolved following the development of academic publishing in early modern Europe in the sixteenth and seventeenth centuries. Publishers, who increasingly rely on the opaque indexing and ranking algorithms of Google and other search engines to drive traffic to their sites, find that their quality content remains mired in relative obscurity. Librarians worry that undergraduates wallow indiscriminately through Google search results, all but ignoring the sources that the library has so carefully vetted, selected, and purchased.
There is a crisis of trust in academic publishing precipitated by the move to online publishing and the attendant deprecation of traditional mechanisms of ensuring the authority and reliability of published works. Some of the problems that have arisen during the move from print to online publishing echo those that occurred during the shift from a manuscript and oral culture to a print culture. In each case, traditional systems for establishing authority and reliability were displaced. It took centuries to build and create the current infrastructure for establishing the authenticity and reliability of scholarly print content.[1] The task of creating new authority mechanisms for online scholarly publishing has hardly begun.
Publishers and librarians have spent a turbulent decade engaged in the transformation of their respective practices. Previously, they were primarily concerned with physical media - the commissioning, production, distribution, curation, and archiving of works of print. Now, they find themselves preoccupied with the development of analogous processes for digital content. With their attention focused on the operational aspects of a move to the digital world, they have not been as aware of the transition from the trust model of the print-based scholarly world to the trust model of the Internet.
Characteristics of Trust
Kieron O'Hara, in his book Trust: From Socrates to Spin, describes how public trust can be characterized using two axes of criteria, global and local, and horizontal and vertical. O'Hara's characterization of public trust helps highlight why the move of scholarly trust mechanisms to the Internet has been so fraught.[2]
O'Hara first describes how public trust can be categorized as either "local" or "global." Local trust is defined as trust that is based on personal acquaintance - trust that one extends to one's family, friends, colleagues, and acquaintances and that is based on direct experience. Though local trust can be very strong, it suffers from one major deficiency - it is not always transitive and, thus, does not scale. Just because I trust my wife, it does not automatically mean that I trust her friends and it certainly doesn't mean that I automatically trust my wife's friends' friends. The degree to which local trust is transitive varies by individual and culture, but its dependence on personal acquaintance limits its scalability.
Global trust, in contrast, O'Hara defines as trust "via proxy." An example of global trust is when you extend trust to a regulatory institution. Global trust is intrinsically transitive - if you trust an auditing firm, you are then able to extend a certain degree of trust to all of the companies that the auditing firm audits without being personally acquainted with those firms. Global trust also has a fundamental weakness in that it is subject to systemic failure - if you lose trust in an auditing firm, then you are also likely to transitively lose whatever trust you had in the companies it has audited.
O'Hara's second axis for characterizing public trust divides trust into "horizontal" and "vertical" trust. Horizontal trust is trust among equals - where there is little possibility of coercion, and no way to enforce norms of behavior. The trust you place in your grocery store is an example of horizontal trust. If the grocery store fails you in some way, you typically have little recourse but to complain. If the store chooses to ignore your complaint, the best you can do is refuse to patronize the store in the future. The fundamental problem with horizontal trust is that it is unenforceable.
In contrast, vertical trust is trust that is granted within an established hierarchy. The key feature of vertical trust is that coercion can be used to enforce trustworthy behavior. A government can put you in jail if you break the law. It is important to note that the authority of the hierarchy in a vertical trust relationship may not itself be imposed. You may choose to join a country club, and in so doing, agree to defer to the club's hierarchy and trust decisions. In this case, failure to meet the club's expectations merely means that you get kicked out of the club.
O'Hara's observations on trust have relevance to scholarly publishing when you contrast the trust models of the Internet with those of academia.
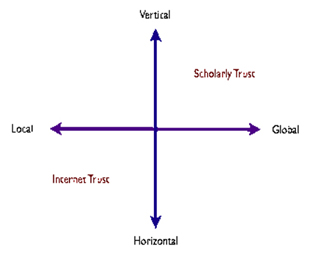
The Internet, although it is a "global" network in the sense that it is available all over the world, employs a "local" trust model. When you use e-mail or the Web, you have few ways to determine the trustworthiness of the content you are reading, other than your personal assessment of the e-mail's sender or the owner of the Website URL. Even then, your trust is tempered by the knowledge that both e-mail addresses and URLs are easy to spoof.[3]
The Internet trust model is also "horizontal." Only ICANN, the organization that assigns and manages Internet addresses, has Internet-wide authority to coercively impose norms of behavior on Internet users.
Where the Internet employs a local trust model, academia employs a global trust model. Schools, universities, departments, societies, and journals are all institutions designed to distribute trust via proxy. A prestigious university transitively confers trust on those to whom it grants degrees, and a high impact-factor journal transitively confers trust on those whose articles it publishes.[4]
The academic trust model is also clearly vertical. Universities, departments, and societies all have methods of imposing norms of behavior in academia - until a scholar is granted tenure. This academic reward virtually removes traditional coercion mechanisms, because the tenured individual has been deemed trustworthy.
Clearly, the academic and Internet trust models are at opposite ends of O'Hara's local/global and horizontal/vertical axes for categorizing public trust. This difference in trust models underlies much of the difficulties in moving academic publishing online.
The Internet Trust Antipattern
Underestimating the role of trust in communications is a common theme in the development of the Internet. Most of the fundamental building blocks of Internet communication - e-mail, Usenet newsgroups, instant messaging, Web search engines and blogs - have all suffered at some time a "crisis of trust" where the very viability of the system is undermined by a lack of infrastructure for assessing reliability and authority. This Internet trust antipattern[5] usually takes the following form:
- System is started by self-selecting core group of high-trust technologists (or specialists of some sort).
- System is touted as authority-less, non-hierarchical, etc. But this is not true (see 1).
- The general population starts using the system.
- The system nearly breaks under the strain of untrustworthy users.
- Regulatory controls are instituted to restore order. Sometimes they are automated, sometimes not.
- If the regulatory controls work, the system is again touted as authority-less, non-hierarchical, etc. But this is not true (see 5).
It is remarkable how many of our most common Internet communications tools have been through the above stages, sometimes more than once. For a time, e-mail seemed in danger of being crippled by a tsunami of spam. Only the development of sophisticated spam detection techniques, the liberal use of blacklists, and the development of trusted mail protocols have managed to keep e-mail usable. It is sobering to note that some once-common communications systems failed to make it through step five and have since languished at the technological fringes. The old Usenet[6] system is a good example of a system that failed to develop effective tools for managing the authority and reliability of content. Even the development of sophisticated filtering user interfaces and "bozo" filters were not enough to stop the Usenet system from eventually drowning in an effluence of flamebait,[7] spam, warez,[8] and pornography.
Avoiding the Internet Trust Antipattern
It is instructive to note that some of the biggest Internet success stories share a willingness to seriously consider the issues of authority and trust, and compensate for the Internet's lack of a trust infrastructure. eBay, Amazon, Slashdot, and Google have all built site-specific mechanisms for managing trust within their communities.
The online auction site eBay realized early on that it had to address the problem of trust. Not only did eBay need to ensure that its clients trusted eBay, it also had to ensure that eBay's clients trusted each other. Toward this end, eBay incorporated a system where buyers and sellers could rate each other after transactions. Each registered user of eBay accumulates a feedback history showing how each of their transactions has been rated. Prospective buyers can look at sellers' feedback histories to determine the level of risk involved in doing business with them. Likewise, sellers can look at a buyer's history to find out if they are dealing with a difficult customer. Participants in the eBay trust feedback mechanism put great store in their ratings because a good rating can help sellers to attract business. eBay has created a form of social feedback loop whereby participants in the system see direct benefit from adhering to the social norms of the auction community.[9]
eBay is not the only Internet success story to make use of a built-in social feedback trust mechanism. The online retailer (I almost wrote "bookstore," which probably dates me as an Internet fossil) Amazon also makes heavy use of client feedback to create a climate of trust conducive to business. In Amazon's case, they encourage all users of their service to "review" products listed on the Amazon site. Amazon clients can quickly learn which reviewers they tend to agree with and actively start to seek out products that have been positively reviewed by trusted reviewers. Amazon has also built systems that encourage users to cite books easily on Amazon, a facility heavily used by bloggers. This mechanism rewards people who cite Amazon (Amazon Associates) with a percentage of any transaction that results. This system creates an additional incentive for taking the trouble to cite references.[10]
Both the eBay and Amazon social feedback mechanisms are designed to increase end-user trust in online purchasing. The geeky uber-blog, Slashdot, has created a social feedback mechanism that allows its users to focus on authoritative and relevant postings. The founders of Slashdot, like many who built discussion forums during the late 1990s - the heyday of so-called "online communities"- found their discussion forums quickly overwhelmed by inanity, ranting, obscenity, and irrelevance. Slashdot created a group moderation system in which registered moderators could rank comments and postings made on the Slashdot site. As a registered user posts highly ranked comments, that registered user gains "karma points" within the community. As a user's karma increases, he or she too can become a moderator, and confer or remove karma points from other users of the system. Even moderators can themselves be "meta-moderated"- a check designed to make sure that moderators did not become too powerful. The benefit of the Slashdot moderation/karma system is that users of Slashdot can filter stories and comments based on the karma points of the authors who make the posts. This allows readers of Slashdot to focus only on highly ranked postings or the postings of well-regarded (authoritative) members of the community.[11]
Google's trust system is largely invisible to the end user; its most prominent external manifestation is whether the results that Google returns from a query are relevant or not. When Google was launched, the Internet search engine field was already populated by heavyweights like Yahoo and Altavista, but such was the improvement in Google's search results that users quickly adopted the newcomer. One of the keys to Google's search results was their ranking algorithm, PageRank. Google's innovation in ranking the relevance of documents was to stop treating documents as discrete units and to instead include an analysis of the citation relationships between documents in relevance ranking. For example, if three documents A, B, and C all seemed to be about "cryptanalysis" and they all linked to a fourth document, D, then the likelihood was high that document D was also about cryptanalysis and, more importantly, was somehow authoritative. Citations are treated as a "vote" for relevance. In effect, Google managed to exploit the Web's linking system as an intrinsic social feedback loop.[12]
eBay, Amazon, Slashdot, and Google have all built their businesses on highly effective mechanisms for managing trust and authority on their respective sites. These trust systems share common characteristics. All are based on user-provided metadata - transaction rankings, reviews, karma votes, and links. Additionally, this metadata is gathered as part of natural user behavior within the context of each site.
By exposing past transaction evaluations, eBay, Amazon, and Slashdot effectively extend the scalability of what is essentially still "local" trust. Additionally, because these three sites require registration in order to fully participate in the trust system, they have also created a vertical trust arrangement, in which users can be banned from using the site if they don't adhere to the community's norms of behavior.
Google, while it has less vertical control than eBay, Amazon, and Slashdot, manages to radically scale local trust by automatically harvesting links (votes for relevance) in a way that would be utterly impractical to do manually.
The trust systems employed by each site also share some common limitations. The most obvious limitation is that each trust system is restricted to a particular site. For example, Amazon reviews and the Slashdot karma do not interact. It might be useful to search Amazon for technical books that have been positively reviewed by a Slashdot member with high "karma," but this is not currently possible.
The other obvious limitation of the trust systems employed by these sites is that they are very coarse: they do not take context or degree into account. On Amazon, you might trust reviewer A's opinions on music, but not on books. On Slashdot, you might respect a poster's expertise on the programming language Java, but not on cryptanalysis.
Social Software and Trust
Recent developments in the area of "social software" point to how trust systems might be employed in a generalized fashion across sites, avoiding some of the limitations of the trust management systems developed by eBay, Amazon, Slashdot, and Google. The term "social software" refers to a broad range of applications including "collaborative writing tools" (e.g., blogs and wikis), "social networking tools" (e.g., Orkut, Friendster, and LinkedIn), and social bookmarking or categorization systems (e.g., Technorati, del.icio.us, Furl, CiteULike, Connnotea, and Flickr).[13]
Blogs are probably the most familiar social software application listed above. These lightweight Web publishing applications allow even the least tech-savvy user to publish to the Web in the now-familiar diary format, where postings are listed in reverse chronological order and archived for easy searching and browsing.[14]
The typical blog application also includes important features that encourage the creation of communities of bloggers. One of the better known of these features is the comments section of a blog where blog readers are encouraged to comment on blog postings. This comment system has, in most modern blogging systems, been further augmented by tools that make it easier for bloggers to cite each other across blogs. Blog software typically creates automatic content syndication feeds (e.g., RSS[15]) from the content posted. This syndicated content can, in turn, be easily incorporated into other blogs. A typical use of this syndication creation and subscription system is the creation of so-called "TrackBack" lists, where a blogger can automatically generate a list of referring blogs.[16]
The ability of blogs to easily syndicate content, and to include syndicated content from elsewhere, facilitates informal cross-site social feedback loops similar to those created using the trust metric systems in eBay, Amazon, Slashdot, and Google. The ability of bloggers to cite each other easily also takes advantage of Google's PageRank algorithm to further amplify the social feedback loop of the "blogosphere." Non-blogging sites can tap into the blogosphere simply by syndicating content and making it available for linking. An academic journal that makes its metadata available via an RSS feed makes it easier for bloggers to cite and refer to content on the journal's site. This in turn allows the journal to leverage the blogosphere's social feedback loop to increase its search engine ranking.

- You browse to a page that interests you and bookmark it.
- You think of several other people who might be interested in the page, so you send them a link to it.
- You keep thinking of more people who might like to see the page; leaving one of them off the list might cause offense.
- You either copy a summary portion of the page or compose a summary yourself.
- Finally, recipient list filled, summary written and link pasted in, you send the link.
- You run across another site that might be interesting to people, and decide not to send it to anybody because you don't want to waste more time going through steps 1-5 again.
With a social bookmarking application, all you have to do is tell your friends and colleagues where they can subscribe to your bookmarks. When you find an interesting or important site, you click a button in your browser to bookmark it centrally. Everybody who subscribes to your bookmarks will be informed of the new bookmark the next time they read their subscription. You, in turn, can subscribe to the bookmarks of people you trust to identify interesting or important sites.
Naturally, social bookmarking tools also allow you to categorize your bookmarks, but rather than using the folder metaphor favored by most browser-based bookmarking facilities, social bookmarking applications allow you to "tag" your bookmarks with your own keywords. With folder-based tagging systems, you often find yourself choosing between filing a bookmark under category "A" or category "B"; with a tagging metaphor you can tag the link as being both "A" and "B."
The categorization aspect of social bookmarking applications has become central to their utility. As a subscriber to bookmarks, you can use the categorization system to create a tag-centric view of the bookmarks recorded in the social bookmarking system. You can, for instance, subscribe to a virtual combined bookmark list of everything that any user has bookmarked and tagged with the word "music." Of course it's unlikely that you'll be interested in all the bookmarks tagged with the word music, so you can instead choose to view only those bookmarks that are tagged with the word music and have been created by people whose opinion on music you trust. In this case, the categorization system lays the foundation for constraining trust relations.
Both blogs and social bookmarking applications show how social software in general can be used to create informal trust systems based on social feedback loops. A researcher can now effectively subscribe to a trusted colleague's virtual real-time research notes (blogs) and annotated bibliographies (bookmarks). By knowing which blogs, sites, and bibliographies their colleagues subscribe to, researchers can begin building simple, cross-site trust overlay filters for the Web.
Like eBay, Amazon, and Slashdot, social software extends the scalability of local trust relationships by exposing metadata recorded while users perform everyday online activities - in these cases, "citing" and "bookmarking." However, unlike the larger, centralized commercial application, social software applications generally don't have the option of falling back on vertical enforcement of norms of behavior.
In this regard, distributed social software applications share a disadvantage with Google: they rely on information gathered from sites beyond their control. Attempting to undermine the integrity of Google's search results and achieve artificially inflated PageRank - a technique known as "Google Bombing"- has become both a business and a sport.[21] Without the option of vertical enforcement, Google has had to rely on augmenting PageRank with a sophisticated set of self-regulating algorithms that attempt to determine when sites disingenuously link to each other in order to manipulate PageRank. Although details of the precise mechanism that Google uses are sparse, there appears to be a degree of transitivity in these calculations, i.e., if a certain site is determined to be unreliable, sites that it link to are also considered less reliable, and their links are, in turn, considered less reliable. This self regulating, algorithmic method for automatically and transitively calculating the reliability of nodes in a network is known as a "trust metric,"[22] and social software applications are turning to the science of trust metrics in an attempt to provide a distributed, reliable, self-regulating, and highly scalable means of trust enforcement in their communities.
The consumer review site, Epinions, employs a state-of-the-art trust metric that rewards high-trust participants monetarily via a mechanism called "Eroyalties."[23] Any registered user can write product reviews (e.g., reviews of electronics, records, movies, books, etc.) for Epinions, and Epinions will pay reviewers a share from all referral fees earned by sending users to sites that advertise on Epinions. The reviewers' shares are proportional to how much their reviews are read, and to the level of "trust" that they are accorded by the community. The Epinion calculation of "trust" is transitive, so "high trust" members confer proportionally more trust in their votes than "low trust" members." Of course if "high trust" users slack off and lose status, their transitive influence on trust assessments declines as well. This Web of trust fundamentally changes the scalability rules of the aforementioned local/global trust axis. An Epinions trust rating can't really be put under O'Hara's category of "local" because it is based on experience beyond that of people you know or have evaluated. Likewise, the trust metric isn't really global, because it isn't dependent on just one trust proxy. The Epinions trust metric in effect uses multiple proxies, and in so doing transcends the scalability problem inherent in local trust, and the risk of systemic failure inherent in global trust.
That Epinions is willing to pay money based on the evaluations of its trust metric indicates a great deal of faith in the system. However, Epinions is also a closed-world system, and as such can always rely on vertical enforcement as a last resort.
An ambitious effort to create a truly universal and distributed Internet trust metric can be found in the experimental "Outfoxed" project by Stanley James.[24] Outfoxed is a combination of a Firefox browser plug-in and a simple server for trading distributed trust information via RSS. Users who have installed the plug-in can register with the server (which could theoretically be part of a distributed network of servers) and publish their trust information whilst simultaneously indicating which other system users they trust (informers). When browsing the Internet with this system, users can add trust information to anything that is addressable with a URI. Thus, they can rate objects at whatever level of granularity a resource supports (e.g., site, page, paragraph, record, etc.).
An Outfoxed user can enter both a trust rating and a "report" that gives added context to the ranking. When a user of the system visits a resource that has been rated by another Outfoxed user, a button appears on the browser toolbar indicating whether the resource is to be trusted or not. You can get details of any existing votes by viewing the reports that were submitted with the trust ratings. Outfoxed even has a feature that embeds trust indicators into Web pages; for instance, a Google results page will be displayed with trust ratings next to each result, or links on a page will be highlighted in specific ways depending on whether they point at a trusted, untrusted, or unrated resource.
Imagine being able to search only those resources that you or your trust network deems authoritative on the subject at hand. Think of what it would be like if you were able to automatically subscribe to the citations of trusted colleagues and the citations of people your colleagues trusted. Outfoxed provides a tantalizing glimpse of what the Internet might feel like if the restrictions of local/global and horizontal/vertical trust can be transcended.
Conclusion
In Jorge Luis Borges's short story, "Tlön, Uqbar, Orbis Tertius", Borges is impressed by a friend's obscure quote and asks him to cite it. The friend, Adolfo Bioy Casares, obliges, saying that he encountered it while reading an entry on the country "Uqbar" in the Anglo-American Cyclopdia. When they go and check Borge's copy of the same edition of the same encyclopedia, not only do they fail to find the quote, but they fail to find the entry on Uqbar. When the embarrassed Bioy Casares goes home, he looks up the entry in his copy of the encyclopedia and finds that it is indeed there. It seems that the two copies of the encyclopedia are identical, except for the addition of the one entry on Uqbar in Bioy Casares's copy. Investigation reveals that the country Uqbar never existed, and that the fictional encyclopedia entry was the result of a vast conspiracy of intellectuals to test Berkeleian idealism by imaging a fictional world in the hopes of actually creating it.
A mere summary of the story does not do justice to the foreboding atmosphere that Borges creates. Modifying a print reference work could not have been a trivial task - it would have required the collusion of countless influential people who were traditionally the guardians of authority and credibility: editors, compositors, printers etc. That the encyclopedia entry was fabricated and inserted into some copies of an otherwise legitimate reference work is shocking, and serves to underscore the power, influence, and cunning of the conspirators.
Today, the much-vaunted Wikipedia makes a virtue of the fact that anyone can add or modify entries in an online encyclopedia. The Wikipedia, along with blogs and social bookmarking tools, is one of the social software success stories. The Wikipedia doesn't use any fancy trust metrics - yet. It relies on the collective oversight of millions of eyeballs, backed up with a seldom-mentioned vertical trust enforcement regime of "administrators," an "arbitration committee," and the founder of the Wikipedia himself, Jimmy Wales.
The quality of the content created by this loose social network of self-appointed editors has, to date, been very high. Indeed, the vast majority of the citations in this article point at Wikipedia entries. The Wikipedia entry on Borges's short story is particularly good. You can snigger at its casual and seemingly entirely unselfconscious admission that "A fictional entry about Uqbar stood unchallenged for some time in the Wikipedia" (from November 6, 2003 to February 23, 2004, to be precise), but the fact remains that the specious entry was corrected and a history of the error was recorded.[25]
Unfortunately, as the Wikipedia grows in popularity and influence, the motivation to vandalize, astroturf,[26] and generally co-opt the editorial process will increase tremendously. There is a risk that the Wikipedia will also succumb to the Internet trust antipattern. Wikipedians have made it clear that they will resist resorting to vertical trust mechanisms for enforcing norms of behavior. Unless the Wikipedia can buck the trend of nearly every other Internet communication system, it seems likely that they too will be looking to trust metrics to help manage their community.
Publishers should watch closely the development of the Wikipedia over the next few years. It is applying to a reference work the kind of social feedback loops that have helped make the fortunes of eBay, Amazon, and Google. It will be interesting to see if the Wikipedia must eventually augment this process with trust metrics.
At the same time, publishers should keep an eye on the development of more generic, social software-based distributed trust systems, keeping in mind John Perry Barlow's observation, in his 1992 article "Selling Wine Without Bottles on the Global Net":
"People are willing to pay for the authority of those editors whose filtering point of view seems to fit best. And again, point of view is an asset that cannot be stolen or duplicated."[27]
Epinions, and to a lesser extent eBay and Amazon, have already shown that there is a market for authoritative opinions, and that adding a monetary element to a trust metric can strengthen it. Publishers will want to focus on understanding and helping to define ways in which the limits of trust on the Internet can be transcended, and what role they can play in helping to establish Internet trust. Trust networks and social software do not preclude a business model; indeed, notable successful Internet business models have been based on them. Academic publishers are experts on expertise and authority. Publishers are naturally positioned to help shape and profit from the development of sustainable Internet trust mechanisms.

NOTES
Elizabeth Eisenstien

O'Hara, Kieron. 2005. Trust: From Socrates To Spin. London: Icon Books Ltd.
Not-so-deep impact, Nature 435(23) (2005) 1003-1004, doi: 10.1038/4351003a
http://www.amazon.com/gp/browse.html/103-4425553-7165429?node=3435371